Beyond Caption-Based Queries for Video Moment Retrieval
Abstract
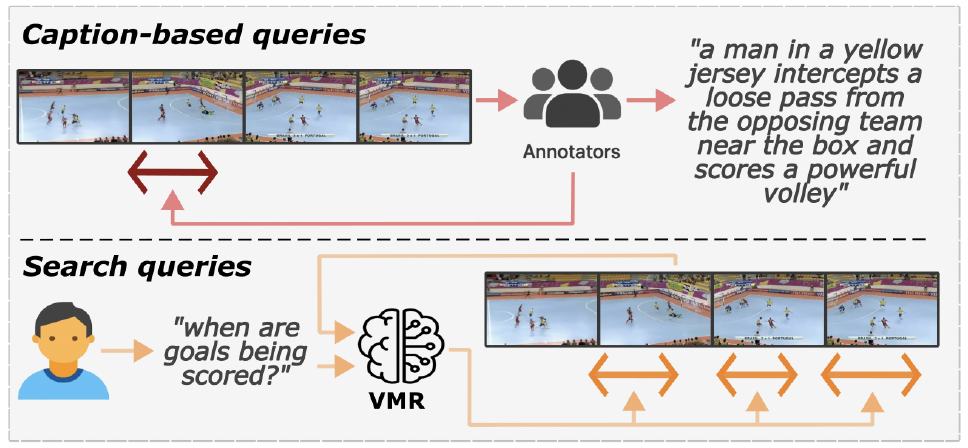
Current Video Moment Retrieval (VMR) models are trained on videos paired with captions, which are written by annotators after watching the videos. These captions are used as textual queries---which we term caption-based queries. This annotation process induces a visual bias, leading to overly descriptive and fine-grained queries, which significantly differ from the more general search queries that users are likely to employ in practice. In this work, we investigate the degradation of existing VMR methods, particularly of DETR architectures, when trained on caption-based queries but evaluated on search queries. For this, we introduce three benchmarks by modifying the textual queries in three public VMR datasets---i.e., HD-EPIC, YouCook2 and ActivityNet-Captions. Our analysis reveals two key generalization challenges: (i) A language gap, arising from the linguistic under-specification of search-queries, and (ii) a multi-moment gap, caused by the shift from single moment to multi-moment queries. We also identify a critical issue in these architectures---an active decoder-query collapse---as a primary cause of the poor generalization to multi-moment instances. We mitigate this issue with architectural modifications that effectively increase the number of active decoder queries. Extensive experiments demonstrate that our approach improves performance on search queries by up to 14.82%, and up to 21.83% mAp_m on multi-moment search queries.
Captions vs. Realistic Search Queries
Standard VMR benchmarks like HD-EPIC or Charades use captions that describe every visual detail (e.g., "The person picks up a silver spoon with their right hand from the wooden table"). In contrast, search logs reveal that humans often use minimal, under-specified queries (e.g., "taking a spoon"). Our analysis shows that VMR performance drops by up to 40% when moving from captions to these realistic search distributions. Importantly, existing benchmarks exhibit a single-moment prior: they predominantly contain queries that refer to a single moment in time. However, real-world search patterns frequently involve multi-moment queries where the same action occurs multiple times, exposing critical limitations in models trained exclusively on single-moment data.
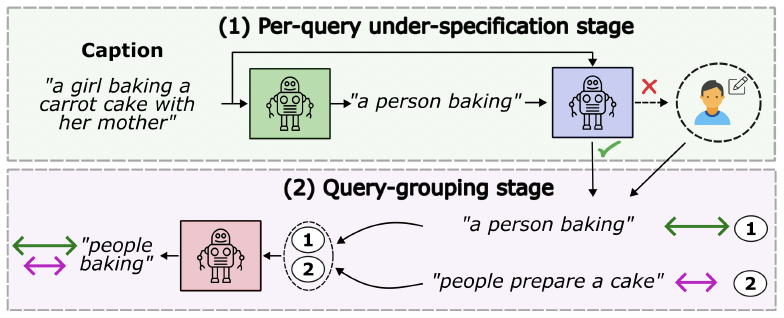
Automated Under-specification Pipeline
To simulate realistic user behavior without manual re-annotation, we propose an automated under-specification pipeline to create search-based benchmark variants (denoted with the suffix "-S"). By leveraging an LLM-driven scheme, we systematically remove visually biased modifiers (color, material, specific spatial relations) while preserving the core action-object intent. This approach allows us to generate under-specified search queries from existing caption-based datasets, enabling evaluation on realistic query distributions without costly manual annotation.
Architectural Modifications
We identify that current DETR-based VMR models suffer from active decoder-query collapse, where only a small subset of the learnable queries contributes to predictions. While common in object detection, this is exacerbated in VMR by the single-moment prior of existing benchmarks. Our modifications target two specific failure modes:
Self-Attention Removal (-SA): We remove the self-attention mechanisms in the decoder to eliminate coordination collapse. This prevents queries from becoming overly synchronized, allowing them to independently specialize for different temporal moments.
Decoder-Query Dropout (+QD): We introduce a stochastic dropout regularizer for the decoder queries to prevent index collapse. This forces the model to distribute information across a broader range of available learnable queries.
Combined, these modifications—-SA+QD—effectively double the number of active decoder queries in some cases, significantly improving retrieval performance on under-specified search queries.
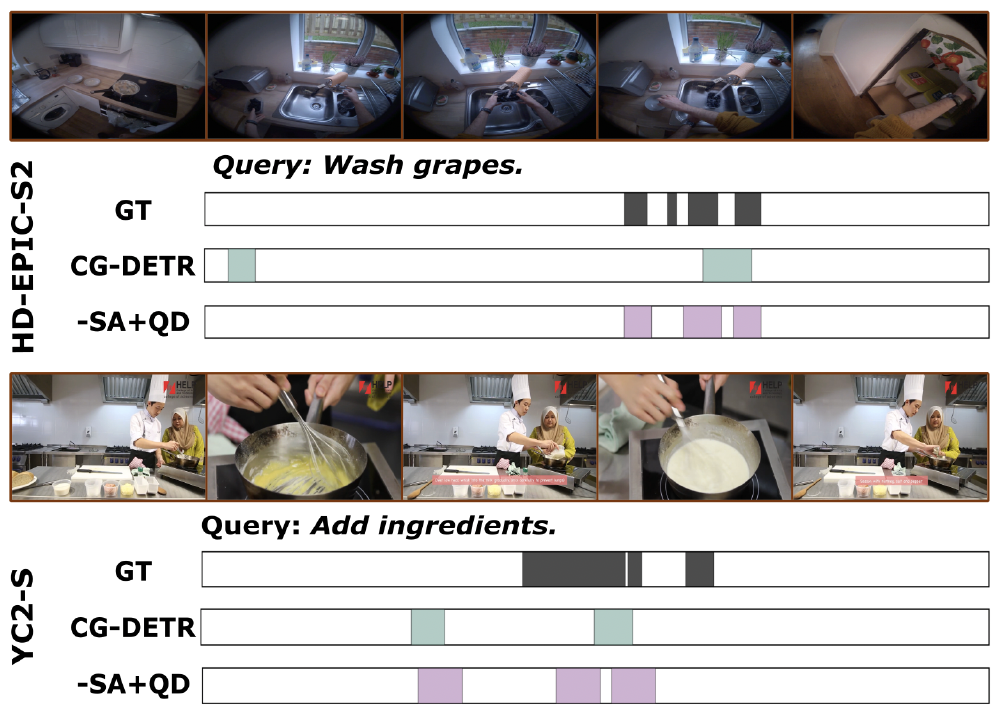
Qualitative Results
Our qualitative analysis on the HD-EPIC-S2 and YC2-S benchmarks reveals that standard models like CG-DETR often struggle to retrieve all relevant segments for under-specified queries. This is primarily because these models only activate a limited number of queries, failing to capture the full temporal extent of the action.
Multi-Moment Coverage: In scenarios containing multiple ground-truth (GT) moments, base models typically suffer from query sparsity—for instance, activating only two queries to retrieve three distinct moments, leaving valid segments localized incorrectly or missed entirely.
Improved Retrieval Diversity: By removing self-attention and introducing query dropout (-SA+QD), our model encourages a larger number of diverse queries to activate. This leads to significantly better coverage and localization for general search queries such as "Wash grapes" or "Add ingredients", where the model must identify multiple occurrences of the same action.