Sparse-Dense Side-Tuner for Efficient Video Temporal Grounding
Abstract
Video Temporal Grounding (VTG) involves Moment Retrieval (MR) and Highlight Detection (HD) based on textual queries. For this, most methods rely solely on final-layer features of frozen large pre-trained backbones, limiting their adaptability to new domains. While full fine-tuning is often impractical, parameter-efficient fine-tuning -- and particularly side-tuning (ST) -- has emerged as an effective alternative. However, prior ST approaches this problem from a frame-level refinement perspective, overlooking the inherent sparse nature of MR. To address this, we propose the Sparse-Dense Side-Tuner (SDST), the first anchor-free ST architecture for VTG. We also introduce the Reference-based Deformable Self-Attention, a novel mechanism that enhances the context modeling of the deformable attention -- a key limitation of existing anchor-free methods. Additionally, we present the first effective integration of InternVideo2 backbone into an ST framework, showing its profound implications in performance. Overall, our method significantly improves existing ST methods, achieving highly competitive or SOTA results on QVHighlights, TACoS, and Charades-STA, while reducing up to a 73% the parameter count w.r.t. the existing SOTA methods.
Efficiency through Sparse-Dense Side-Tuning
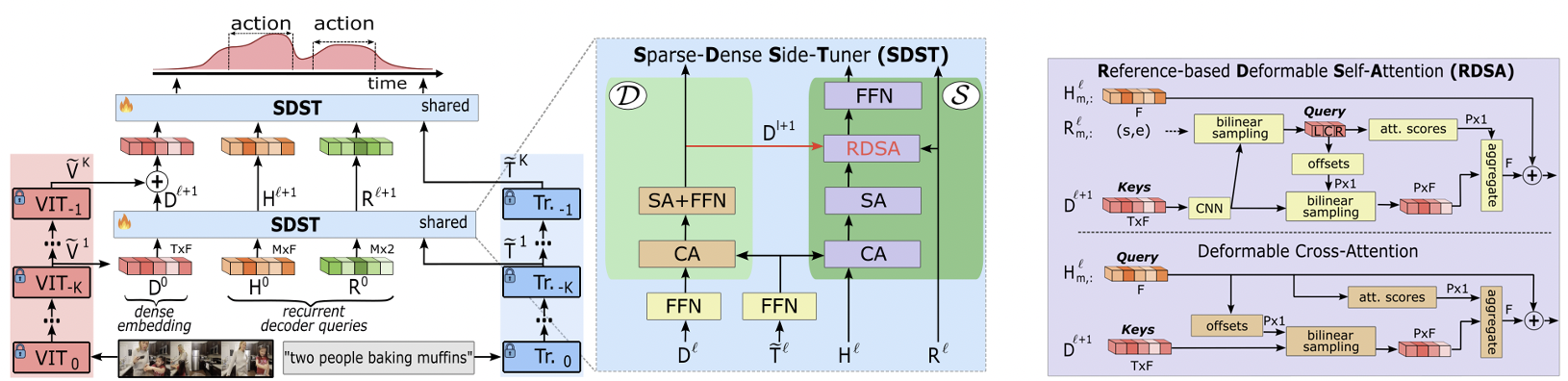
We propose the first sparse-dense module for parameter-efficient video grounding. Our approach relies on Side-Tuning—a paradigm where the heavy video backbone remains completely frozen, and task-specific knowledge is learned through a lightweight parallel network. Unlike standard fine-tuning, which is computationally prohibitive, or traditional adapters that can still be memory-intensive, our side-tuner is specifically designed to be both time and memory efficient.
The module employs a unique sparse-to-dense strategy: it first extracts a sparse set of global temporal features to understand the high-level video context, then selectively decodes these into dense moment-level predictions. This separation allows us to leverage the massive representational power of frozen foundation models while training only a fraction of the parameters, enabling state-of-the-art performance on consumer-grade hardware.
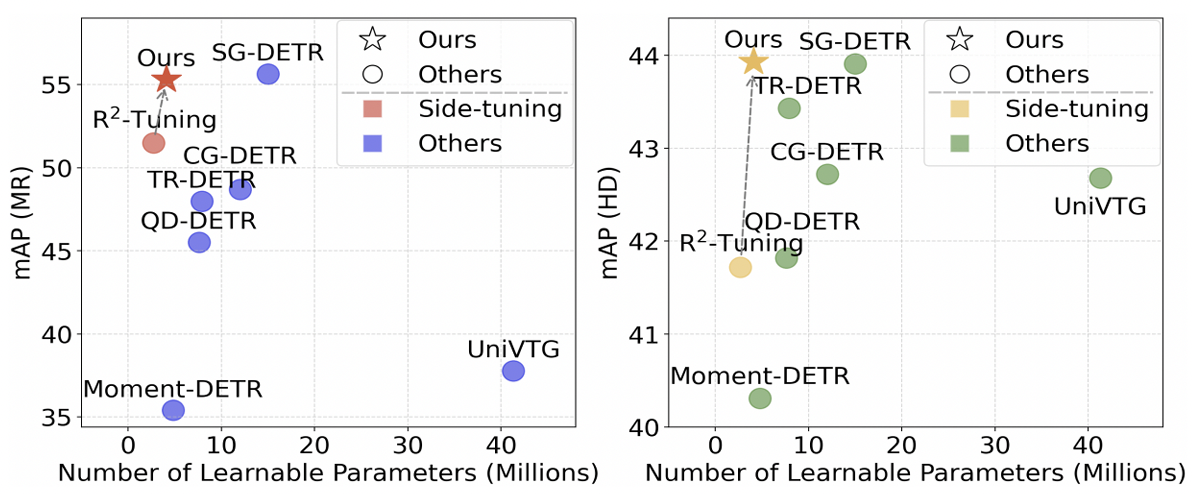
Performance and Scalability
Evaluation on benchmarks like Charades-STA and ActivityNet Captions demonstrates that the Sparse-Dense Side-Tuner matches or exceeds the performance of fully fine-tuned models. More importantly, it shows remarkable scalability in terms of memory, time and parameters, allowing for the deployment of VTG systems on hardware with limited resources.
Bibliography
@inproceedings{pujol2025sparse,
title={Sparse-dense side-tuner for efficient video temporal grounding},
author={Pujol-Perich, David and Escalera, Sergio and Clap{\'e}s, Albert},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={21515--21524},
year={2025}
}